-
[Infra] Apache Kafka프로젝트/당일 2024. 6. 6. 16:21
Apache Kafka 왜 궁금했을까❓
당일 서비스에서 WebSocket으로 서버 간의 통신을 지원했는데 안정성과 장애 복구 등에 취약하다는 것을 알고 Kafka로 전환하기로 결정했다. 어느 정도 개념은 알고 있지만 자세하게는 알지 못해 이번 기회에 깊이 공부해 보려고 한다.
1. Apache Kafka란?
- Apache Kafka는 대규모 실시간 데이터 스트리밍을 처리하는 데 사용하는 분산 이벤트 스트리밍 플랫폼이다.
- Pub-Sub 모델의 메시지 큐 형태로 동작하며 분산 환경에 특화되어 있다.

https://www.confluent.io/blog/event-streaming-platform-1 - Kafka가 도입되기 전에는 위와 같이 서버 간의 End-to-End로 연결되어 데이터를 주고받았다.
- 이로 인해, 서비스의 복잡도가 증가하고 확장이 어려워지며 장애 발생 가능성도 증가하는 문제점이 존재한다.

https://www.confluent.io/blog/event-streaming-platform-1 - Kafka가 도입하고 나서는 모든 데이터와 흐름을 중앙에서 관리할 수 있게 되었다.
- 서비스 장애가 발생해도 데이터 유실 및 중복을 대처할 수 있기 때문에 장애를 유연하게 처리할 수 있다.
- 또한, Scale out이 용이한 시스템으로 서비스의 확장도 유연하며 개발자들은 각 서비스 간의 연결이 아닌 비즈니스 로직에 집중을 할 수 있다.
2. Kafka 동작 방식
Kafka는 Pub-Sub 모델의 메시지 큐 형태로 동작하며 이를 이해하기 위해서는 메시지/이벤트 브로커와 메시지 큐에 대한 이해가 선제적으로 필요하다.
2.1. 메시지 큐(Message Queue)란?
메시지 큐는 메시지 지향 미들웨어(MOM - Message Oriented Middleware)를 구현한 시스템으로 데이터를 교환할 때 사용하는 기술이다.

- Producer는 데이터를 제공
- Consumer는 데이터를 받아서 사용
- Message Queue는 데이터를 임시 저장하고 Consumer에게 제공
- Producer와 Consumer는 직접적으로 통신하지 않고 중간의 MQ를 거쳐 데이터의 교환이 이뤄진다.
2.2. 메세지 큐의 장점
- 비동기 - MQ에 데이터를 임시 저장함으로써 나중에 처리가 가능하다.
- 낮은 결합도 - 서비스 간의 End-to-End로 연결되어 있지 않아 결합도가 낮아진다.
- 확장성 - Producer/Consumer 서비스 간의 연결을 신경 쓰지 않아도 되기 때문에 확장성이 용이하다.
- 보장성 - Consumer의 서비스가 다운되더라도 MQ에 남아있으며 Consumer에 메시지가 전달되는 것을 보장한다.
2.3. 메세지 브로커
- Publisher가 발행한 메시지를 큐에 저장하고 Consumer가 가져갈 수 있도록 중간 다리 역할을 하는 브로커이다.
- Pub/Sub 구조이며 Consumer가 데이터를 가져가게 되면 일정 시간 내에 큐에서 데이터가 삭제된다.
- 서로 다른 시스템 사이에서 데이터를 비동기 형태로 처리하기 위해 주로 사용하며 대표적으로 Redis, RabbitMQ, GCP Pub/Sub, AWS SQS 등과 같은 서비스가 있다.
2.4. 이벤트 브로커
- 이벤트 브로커 역시 메시지 브로커의 큐 기능을 보유하여 메시지 브로커의 역할을 할 수 있다.
- 가장 큰 차이점은 Publisher가 발행한 이벤트를 처리 후에 바로 삭제하지 않고 저장한다.
- 이벤트 시점이 저장되어 있어서 Consumer가 특정 시점부터 처리할 수 있다는 장점이 있다.
- 대용량 처리에 있어서는 메시지 브로커보다 많은 양의 데이터를 처리할 수 있으며 대표적으로 Kafka, AWS Kinesis 등과 같은 서비스가 있다.
2.5. Pub/Sub 모델

- End-to-End 모델에서는 객체가 직접 연결되어 있어 속도가 빠르고 처리 결과를 신속하게 알 수 있다는 장점이 있다.
- 하지만, 장애가 발생한다면 복구할 수 없으며 시스템이 많아질수록 관리가 힘들어져 확장성이 좋지 않다는 단점이 있다.
- 이러한 문제점들을 극복하기 위해 나온 것이 Pub/Sub 모델로 Publisher는 수신자를 정해놓지 않고 Topic에 메시지를 전송하고 Consumer는 Topic에 Subscribe만 하고 있다면 메시지를 수신할 수 있다.
- 이처럼 각 시스템과의 결합도를 낮춰 높은 확장성을 확보할 수 있게 된다.
3. Kafka 구성 요소
3.1. 브로커(Broker)
- 1개의 Kafka 서버를 Broker라고 하며 Publisher로부터 메시지를 수신하고 Offset를 지정한 후 디스크에 저장한다.
- Consumer의 Partition 읽기 요청에 응답하고 디스크에 저장된 메시지를 전송한다.
- Cluster의 구성원으로 동작하도록 설계되었으며 다수의 브로커가 하나의 Cluster에 포함될 수 있다.
- Cluster의 Broker 중 하나는 Controller 역할을 수행하여 Cluster 내의 각 Broker들에게 Partition을 할당하고 Broker가 정상적으로 작동하는지 모니터링한다.
3.2. 클러스터(Cluster)

Kafka : The Definitive Guide 54p - 분산되어 있는 여러 개의 서버를 네트워크로 연결하고 하나의 서버처럼 동작하게 만드는 것으로 Server Clustering이라고 한다.
- 특정 서버에서 장애가 발생하더라도 다른 서버에서 요청을 처리할 수 있어서 가용성을 확보할 수 있다.
- Cluster에 Kafka 서버를 추가할 때마다 메시지 수신과 전달에 대한 처리량이 증가하여 확장성을 확보할 수 있다.
3.3. 토픽 / 파티션 (Topic / Partition)

- Kafka의 메시지는 Topic으로 분류되는데 하나의 Topic은 여러 개의 Partition으로 구성될 수 있다.
- 메시지는 Partition에 추가되며 맨 앞에서부터 끝으로 메시지를 읽는다.
- 메시지의 처리 순서는 Topic이 아닌 Partition별로 관리되며 서로 다른 서버에 분산될 수도 있다.
- 이로 인해, 하나의 Topic을 여러 서버에 걸쳐 수평적으로 확장하면 단일 서버로 처리할 때보다 더 높은 성능을 가질 수 있다.
3.4. 메시지 (Message)
- Kafka 데이터의 기본 단위를 메시지라고 하며 Byte 배열의 데이터로 어떠한 형태의 데이터도 저장과 조회가 가능하여 서비스에 맞게 데이터를 변환해서 사용하면 된다.
- Kafka의 메시지는 Topic 내에 Partition에 기록되는데, 이때 저장될 Partition을 결정하기 위해 메시지에 담긴 키 값을 해시하고 그 값과 일치하는 Partition에 메시지를 기록한다. (이러한 과정을 Partitioner라고 지칭한다)
- 만약, 키 값이 null로 전달되면 Kafka 내부의 기본 Partitioner는 각 Partition 메시기 개수의 균형을 맞추기 위해 라운드 로빈 방식(Round-Robin)으로 메시지를 기록한다.
3.5. 프로듀서 / 컨슈머 (Producer / Consumer)

https://kontext.tech/diagram/1159/kafka-offset-explained - Producer는 새로운 메시지를 특정 Topic에 생성하는데 어떠한 Partition에 기록하는 것은 관여하지 않는다.
- 만약, Producer가 메시지를 특정한 Partition에 기록하고 싶다면 메시지의 키와 Partitioner를 활용하면 된다.
- Consumer는 1개 이상의 Topic을 구독하고 메시지가 생성된 순서대로 읽는다.0
- Conusmer는 메시지를 읽을 때마다 Partion 단위로 Offset을 유지하여 메시지의 위치를 알 수 있다.
- Offset은 Commit Offset과 Current Offset이 있는데 Commit Offset은 처리 완료된 메시지를 확인하는 Offset이고 Current Offset은 어디까지 메시지를 읽었는지 알 수 있는 Offset이다.
- Partition마다 Offset이 있기 때문에 Consumer는 장애나 재시작을 하더라도 메시지를 다시 읽을 수 있다.
3.6. 컨슈머 그룹 (Consumer Group)
- Consumer는 Consumer Group에 속하게 되며 여러 개의 Consumer가 같은 Group에 속할 때에는 각 Consumer가 Partition을 분담해서 메시지를 읽을 수 있다.
- 하나의 Consumer Group에 많은 Consumer를 추가하면 Topic의 데이터 소비를 확장하여 성능을 향상시킬 수 있다.
- 각 Partition은 하나의 Consumer만 처리할 수 있어서 Consumer가 Partition보다 많은 것은 의미가 없으며 특정 Parittion에 대응되는 것을 Partition Ownership으로 불린다.
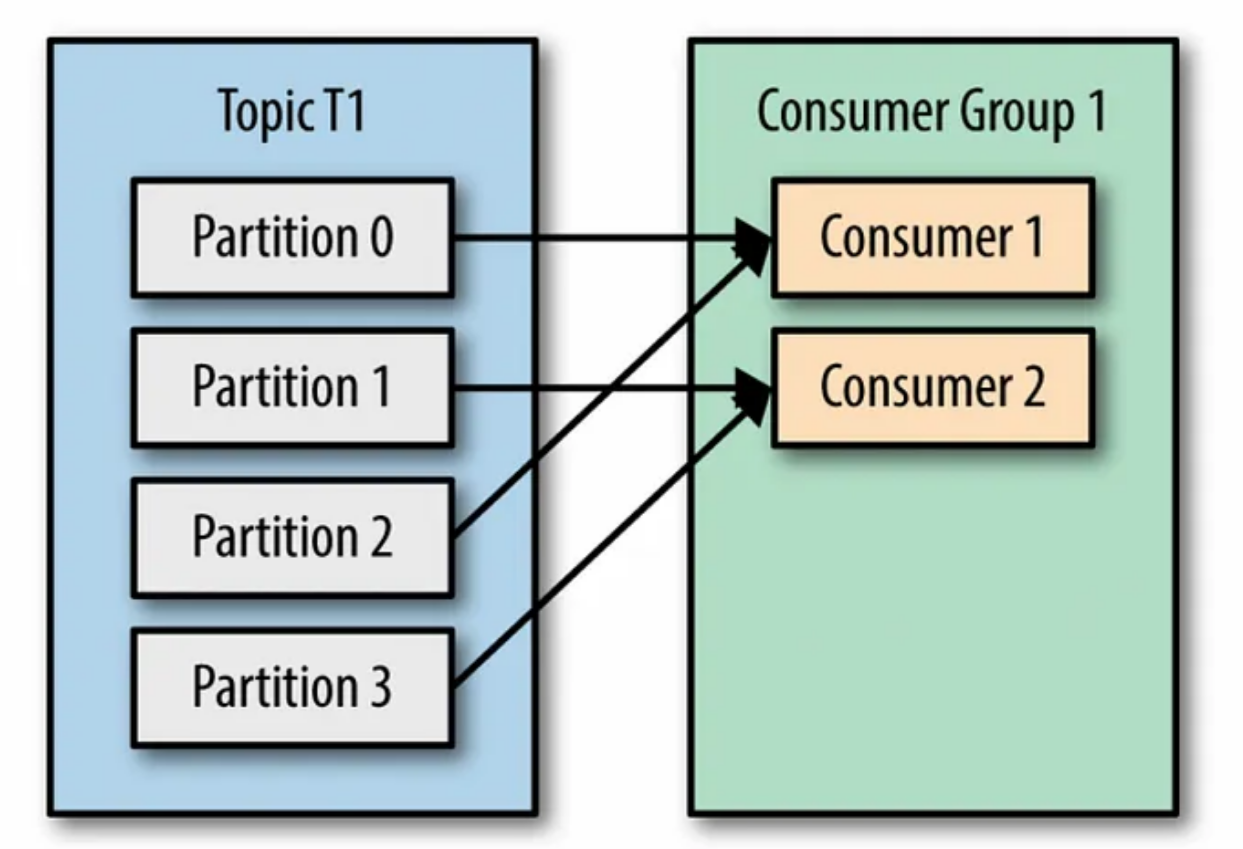
4개의 Partiton에 2개의 Consumer 대응 (Kafka : The Definitive Guide 87p) 
4개의 Partition에 4개의 Conusmer 대응 / 최대 읽기 성능 (Kafka : The Definitive Guide 88p) 
4개의 Partition에 5개의 Consumer 대응 / 오버 스펙 (Kafka : The Definitive Guide 88p) - 하나의 Topic에 여러 개의 Consumer Group이 연결되어 메시지를 읽을 수 있도록 다중 Consumer 기능을 제공한다.
- Consumer Group은 상호 간섭 없이 각자의 Offset으로 순서에 맞게 메시지를 처리할 수 있다.
- 동일한 Topic의 메시지를 읽어야 하는 여러 개의 서비스가 있다면 각 서비스마다의 Consumer Group을 갖게 하고 Group 명을 서비스 이름과 일치하여 관리한다.
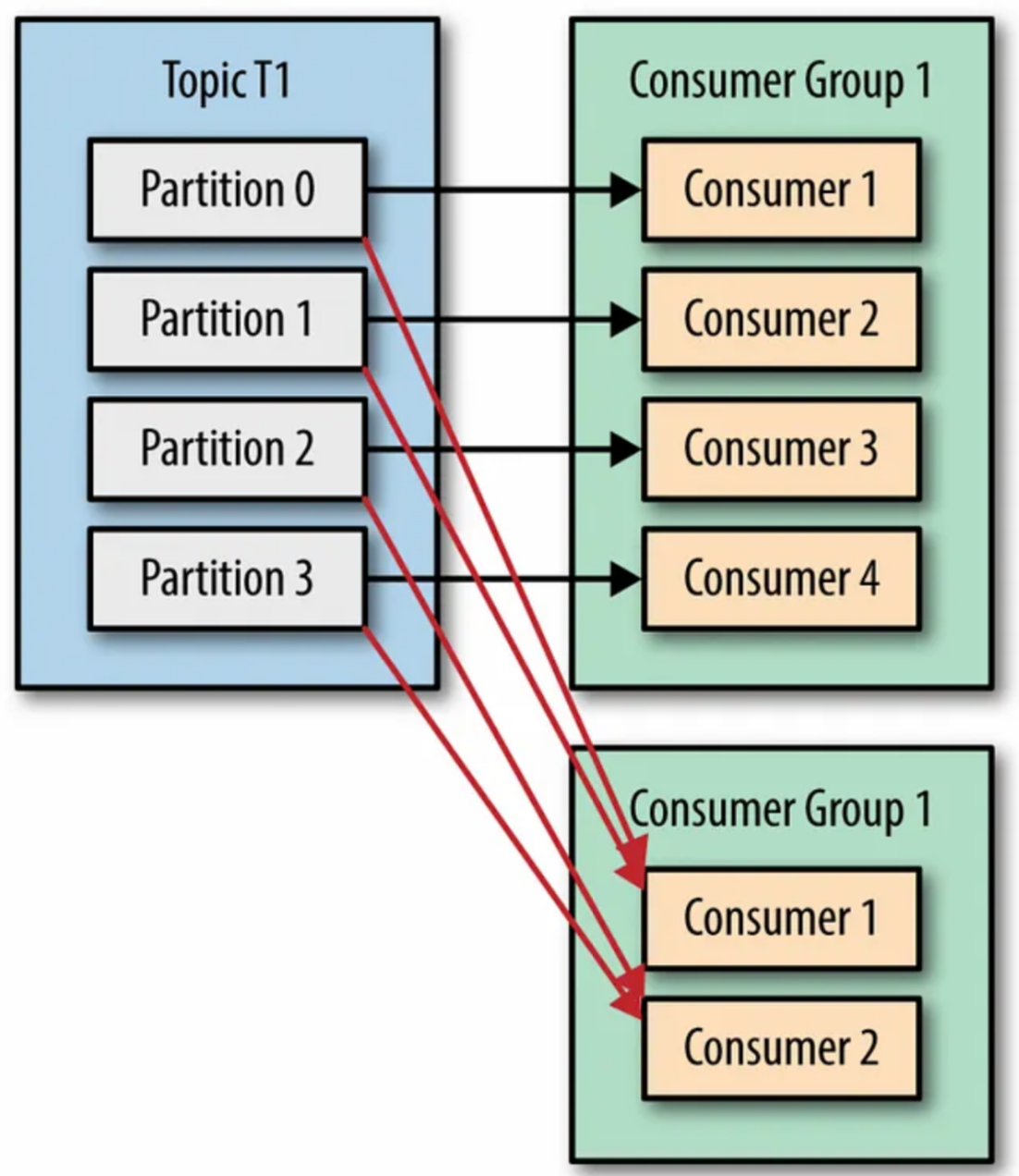
1개의 Topic에 여러 개의 Conusmer Group이 메시지 수신 가능 (Kafka : The Definitive Guide 89p) 3.7. 리밸런싱 (Rebalancing)
- A Consumer로의 Partition Ownership이 B Conusmer에게 이전되는 것을 리밸런싱이라고 하며 가용성과 확장성을 높인다.
- Consumer Group에 Consumer가 추가되면 특정 Partition의 소유권을 신규 Consumer에게 넘겨줄 수 있어야 한다.
- 또한, 장애가 발생한 Consumer가 존재한다면 Partition Ownership을 회수하여 다른 Consumer에게 넘겨줌으로써 성능과 가용성을 확보할 수 있다.
- 이 외에도, Consumer Group이 바라보는 Topic에 새로운 Partition이 생긴다면 리밸런싱이 이뤄진다.
- 리밸런싱이 이뤄지는 동안 Consumer들은 메시지에 읽을 수 없는 상태에 빠지기 때문에 리밸런싱을 적절하게 수행해야 한다.
3.8. 리플리케이션 (Replication)
각 Partition은 다수의 복제 Partition을 가질 수 있으며 2가지 형태가 존재한다.
리더 리플리카 (Leader Replica)
각 Partition은 Leader로 지정된 하나의 Replica를 갖고 일관성을 보장하기 위해 모든 Producer와 Consumer의 요청은 Leader를 통해 처리된다.
팔로워 리플리카 (Follower Replica)
각 Partition의 Leader를 제외한 나머지 Replica로 Consumer의 요청을 처리하지 않고 Leader의 메시지를 복제하여 일관성있는 상태를 유지한다. Leader Replica가 중단되는 경우에는 Follower Replica 중의 1개가 Leader로 선발된다.
- Leader Replica와 동기화 하기 위해서 Follower Replica는 Fetch 요청을 전송하는데 Consumer가 메시지를 읽기 위해 전송하는 것과 동일하다.
- 최신 메시지를 요청하는 Follower Replica를 In-Sync-Replica(ISR)이라고 하며 그렇지 않은 Replica는 Out-Sync-Replica라하며 추후 Leader로 선발될 수 없다.
'프로젝트 > 당일' 카테고리의 다른 글
[Network] Socket, WebSocket, SockJS, STOMP (0) 2024.06.05 [Spring Boot / React Native] FCM을 활용한 알람 서비스 구축 (0) 2024.06.05 [Infra] Kafka를 통한 Spring Boot - FastAPI 통신 (0) 2024.06.03 [Infra] STOMP를 통한 Spring Boot - FastAPI 통신 (0) 2024.06.02 [FastAPI] AWS S3를 활용한 이미지 저장 (0) 2024.06.01